2.2 Choosing Test Cases#
Testing is incredibly important. Software on its own, without strong evidence of its correctness, is of no value. In fact, in many workplaces, the tools used by professionals to manage groups of software developers working on a shared code base won’t accept a contribution of new or modified code unless it contains—and passes—a thorough test suite.
We’ve talked about using a combination of two strategies for testing:
doctest and
unit tests (we’ll use pytest to implement these).
We’ve also talked a bit about how to choose test cases for a test suite. Let’s look at this more closely.
An example#
Suppose max didn’t exist in Python and we were writing a function to find the largest element in a list of integers.
Suppose that we have tested the function on the following test cases,
and that it passes them all:
List |
Expected Result |
Test passed? |
|---|---|---|
|
|
yes |
|
|
yes |
|
|
yes |
|
|
yes |
|
|
yes |
|
|
yes |
|
|
yes |
Would you be confident that the function works? Maybe not—we only checked 7 cases. What if you were shown that it passed 20 more tests? How about 100 more? Even if it passes 1,000 test cases, you should be skeptical. That may be a lot of tests, but think about how many possible ways there are to call this function. How do we know the tests don’t omit a scenario that could cause failure?
The fundamental problem is that we want to be sure that the code works in all cases but there are too many possible cases to test. In this Venn diagram, each circle represents a possible call to the function (of course there are many more than we could draw). Some of them have been tested.

Making a convincing argument#
We may not be able to test every case, but we can still make a convincing argument as follows:
Divide all possible calls to the function into meaningful categories.
Pick a representative call from each category.
Our Venn diagram now looks more organized:
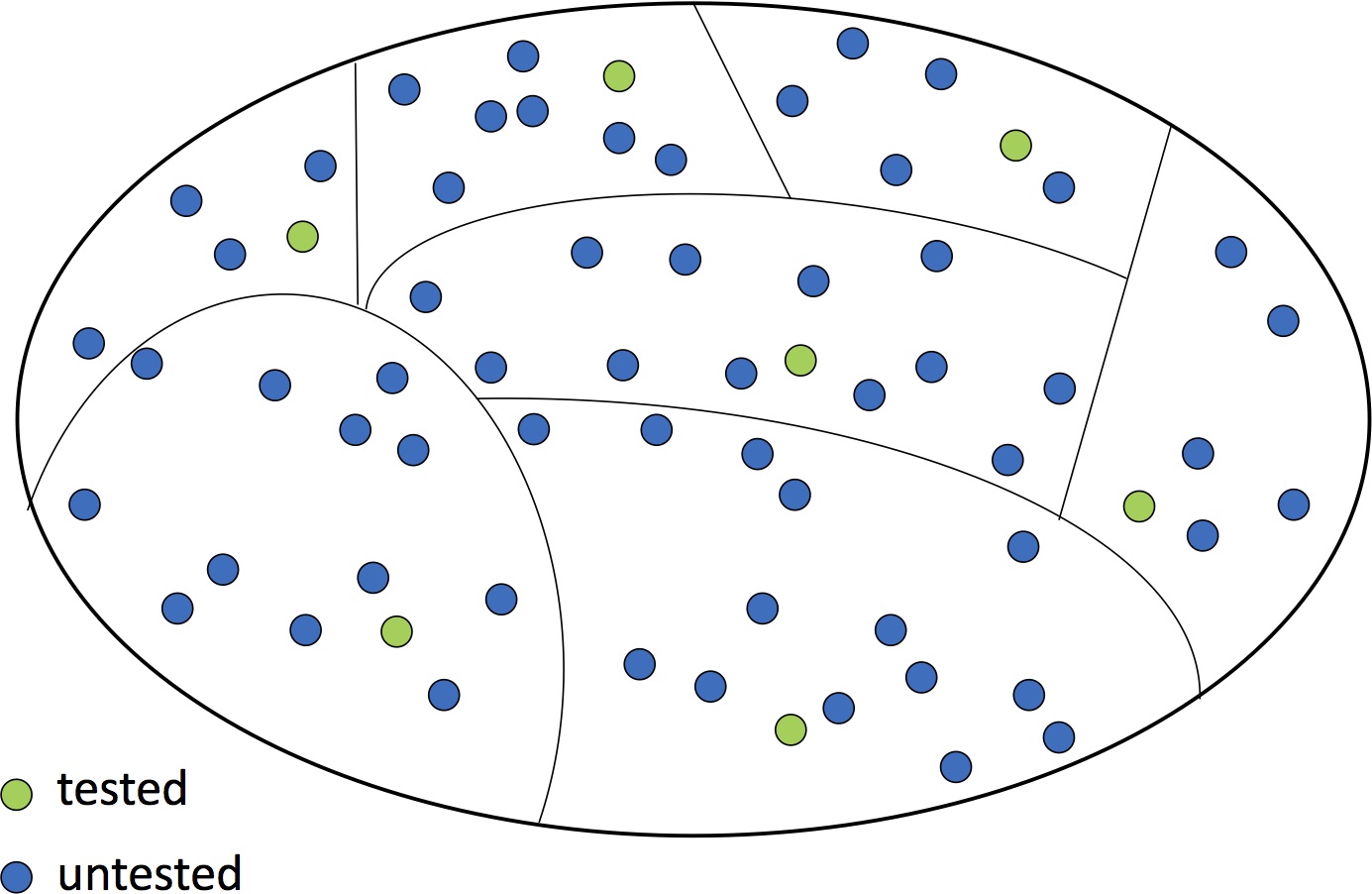
If we choose the categories well, for each category it will be reasonable to extrapolate from that one tested call to all the calls in the category:
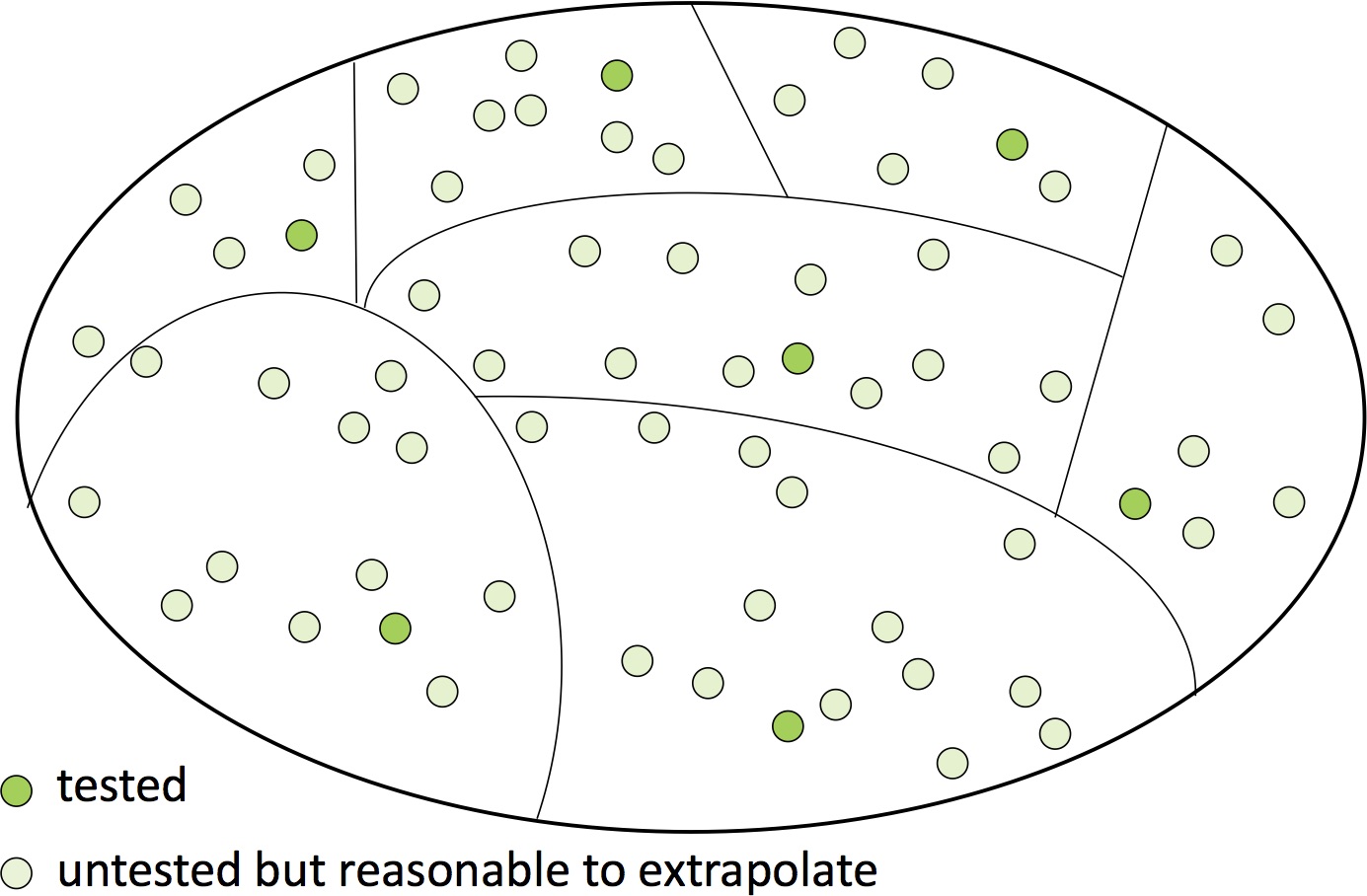
We now have either demonstrated or reasonably inferred correctness in every case.
How to choose the relevant properties#
This kind of argument depends heavily on choosing appropriate categories. We base the categories on properties of the inputs. For example, extending what we saw in an earlier reading, here are some properties and some values for each property:
the size of an object (could be a list, string, etc.): 0, 1, larger, even, odd
the position of a value in an ordered sequence (such as a list or string): beginning, ending, elsewhere
the relative position of two values in an ordered sequence: adjacent, separated
the presence of duplicates: yes, no
ordering: unsorted, non-decreasing, non-increasing
the value of an integer: 0, 1, positive, negative, “small”, “large”, even, odd
the value of a string: alphanumeric characters only, special characters like punctuation marks
the location of whitespace in a string: beginning, ending, elsewhere, multiple occurrences, multiple adjacent whitespace characters, different types of whitespace characters
and more! Depending on the parameters of a function, there could be many other properties.
Not all of these properties are relevant to any particular function. We decide which are relevant based on knowing what the function does. If we also know how the function does it, that can influence our choices as well. For instance, if the function divides a list in half, odd vs. even size is pretty important!
Judgment is also required in choosing which combinations of these properties to test. There is no right or wrong answer here, but a great way to think of it is this: Try to break the code. If you use a good strategy and can’t break it, you have a good argument that it truly works.