1.1 The Python Memory Model: Introduction#
Before we dive into the CSC148 material proper, we’ll review a few fundamental concepts from CSC108. We start with one of the most important ones: how the Python programming language represents data.
Data#
All data in a Python program is stored in objects that have three components: id, type, and value. We normally think about the value when we talk about data, but the data’s type and id are also important.
The id of an object is a unique identifier,
meaning that no other object has the same identifier.
Often Python uses the memory address of the object as its id,
but it doesn’t have to;
it just has to guarantee uniqueness.
We can see the id of any object by calling the id function:
>>> id(3)
1635361280
>>> id('words')
4297547872
We can see the type of any object by calling the type function:
>>> type(3)
<class 'int'>
>>> type('words')
<class 'str'>
An object’s type determines what functions can operate on it.
For example, we can call the function round on numeric types
(such as int and float), but not on strings:
>>> round(2)
2
>>> round(3.1419)
3
>>> round('hello!')
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: type str doesn't define __round__ method
Types also determine the objects on which we can use built-in Python operators.[1]
For example, the + operator works on two integers,
and even on two strings,
but is not defined for adding an integer and a string together:
>>> 3 + 4
7
>>> 'hey' + 'hello'
'heyhello'
>>> 3 + 'hello'
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'int' and 'str'
>>> 'hello' + 'goodbye'
'hellogoodbye'
Finally, you are already familiar with accessing the value of an object, which we call evaluating the object. For example, this is what happens when we type an object into the Python terminal:
>>> 3
3
>>> 'hello'
'hello'
Variables#
All programming languages have the concept of variables.
In Python, a variable is not an object, and so does not actually store data;
it stores an id that refers to an object that stores data.
This is the case whether the data is something very simple like an int
or more complex like a str.
Consider this code:
>>> x = 3
>>> x
3
>>> type(x)
<class 'int'>
>>> id(x)
1635361280
>>> word = 'bonjour'
>>> type(word)
<class 'str'>
>>> id(word)
4385008808
The state of memory after the above piece of code executes is this:

We write the id and type of each object in its upper-left corner
and upper-right corner, respectively.
The actual object id reported by the id function
has many digits, and its true value isn’t important;
we just need to know that each object has a unique identifier.
So for our drawings we make up short identifiers such as id92.
Notice that there is no 3 inside the box for variable x.
Instead, there is the id of an object whose value is 3.
We say that x refers to this object,
or that x references this object.
The same holds for variable word;
it references an object whose value is 'bonjour'.
Here are a couple of other things to notice:
Since we did not write the code for the class that defines the
strtype, we know nothing about what data members it uses to store its contents. So we just write the value'bonjour'inside the box. This is a perfectly fine abstraction.We didn’t draw any arrows. Programmers often draw an arrow when they want to show that one thing references another. This is great once you are very confident with a language and how references work. But in the early stages, you are much more likely to make correct predictions if you write down references (you can just make up id values) rather than arrows.
We can reassign a variable so that it refers to a new value. For instance:
>>> cat = 'Gilbert'
>>> id(cat)
4348845448
>>> cat = 'Chairman Meow'
>>> id(cat)
4355636784
In this example, there is only one variable named cat.
At first it contains the id of a str object containing the string Gilbert,
and then the id in it changes to be that of a str object containing the string Chairman Meow.
These examples are extremely simple, but having an accurate image will be necessary in order to avoid bugs in the much more complex code that we will write this term.
Objects have a type, but variables don’t#
We saw above that Python will report to us what type(word) is.
But it is really reporting the type of the object that word refers to.
The variable word itself has no type.[2]
In fact, Python doesn’t mind if we make word refer now to a different type of
object, although this is almost surely a bad idea.
>>> word = 'adieu'
>>> type(word)
<class 'str'>
>>> word = 42
>>> type(word)
<class 'int'>
Assignment statements and evaluating expressions#
You’ve written code much more complex than what’s above, but may not have had to think in detail about all the small steps that Python has to undertake to execute even a simple assignment statement. These details are foundational for writing and debugging the more complex code you will work on in csc148. So let’s pause for a moment and be explicit about two things.
Executing an assignment statement#
This is what Python does when an assignment statement is executed:
Evaluate the expression on the right-hand side, yielding the id of an object.
If the variable on the left-hand-side doesn’t already exist, create it.
Store the id from the expression on the right-hand-side in the variable on the left-hand side.
Evaluating an expression#
An assignment statement always has an expression on the right-hand side. Expressions can occur in other places also, for instance as arguments to a function call. When an expression is encountered, it must be evaluated. This always yields a value, which is the id of an object.
This is what Python does when an expression is evaluated:
If the expression is a variable, find the variable. If it doesn’t exist, this is an error. If it does exist, the value of the expression is the id stored in that variable.
If the expression is a “literal value”, such as
176.4or'hello', create an object of the appropriate type to hold it. The value of the expression is the id of that object.If the expression is an operator, such as
+or%, evaluate its two operands, apply the operator to them, and create a new object of the appropriate type to hold the result. The value of the expression is the id of that object.
There are additional rules for other types of expression, but these will do for now.
Mutability#
Immutable data types#
Some data types in Python (e.g., integers, strings, and booleans) are immutable, meaning that the value stored in an object of that type cannot change.
For example, suppose we have the following code:
>>> prof = 'Diane'
>>> id(prof)
4405312456
>>> prof = prof + ' Horton'
>>> prof
'Diane Horton'
>>> # The old str object couldn't change, so Python made a new
>>> # str object for the variable prof to refer to. Since it's
>>> # a new object, it has a different id.
>>> id(prof)
4405308016
We did not change the value stored in the object—we couldn’t, since strings are immutable—but rather changed what prof refers to,
as shown here:

From now on, we will use the convention of drawing a double box around objects that are immutable. Think of it as signifying that you can’t get in there and change anything.
Notice that in the example above
we reassigned the variable prof—that is, we made it refer to a new str object—
and we could do this even though strings are immutable.
Regardless of the mutability of any objects,
we can always reassign a variable.
Mutable data types#
More complex data structures in Python are mutable, including lists, dictionaries, and user-defined classes. Let’s see what this means with a list:
>>> x = [1, 2, 3]
>>> x
[1, 2, 3]
>>> type(x)
<class 'list'>
>>> id(x)
50706312
Below, we perform two mutating operations on x, and check that its id hasn’t changed.
Note that even changing the list’s size doesn’t change its id!
>>> x[0] = 1000000
>>> x
[1000000, 2, 3]
>>> id(x)
50706312
>>> x.extend([10, 20, 30])
>>> x
[1000000, 2, 3, 10, 20, 30]
>>> id(x)
50706312
Here’s what’s going on in memory:

The lines x[0] = 1000000 and x.extend([10, 20, 30])
changed the value of the list object that x refers to.
We say that these lines mutate the object that x refers to.
(They also cause the creation of four new objects of type int.)
Aliasing#
When two variables refer to the same object, we say that the variables are aliases of each other.[3]
Consider the following Python code:
>>> x = [1, 2, 3]
>>> y = [1, 2, 3]
>>> z = x
x and z are aliases, as they both reference the same object.
As a result, they have the same id.
You should think of the assignment statement z = x as saying
“make z refer to the object that x refers to.”
After doing so, they have the same id.
>>> id(x)
4401298824
>>> id(z)
4401298824
In contrast, x and y are not aliases.
They each refer to a list object with [1, 2, 3] as its value,
but they are two different list objects, stored separately in your computer’s memory.
This is again reflected in their different ids.
>>> id(x)
4401298824
>>> id(y)
4404546056
Here is the state of memory after the code executes:

Aliasing and mutation#
Aliasing is often a source of confusion for beginners, because it allows “action at a distance”: the modification of a variable’s value without explicitly mentioning that variable. Here’s an example:
>>> x = [1, 2, 3]
>>> z = x
>>> z[0] = -999
>>> x # What is the value?
The third line mutates the value of z.
But without ever mentioning x, it also mutates the value of x!
We call this a side effect.
Imprecise language can lead us into misunderstanding the code.
We said above that
“the third line mutates the value of z”.
To be more precise,
the third line mutates the object that z refers to.
Of course we can also say that it mutates the object that x refers to—they are
the same object!
A clear diagram like this can really help:
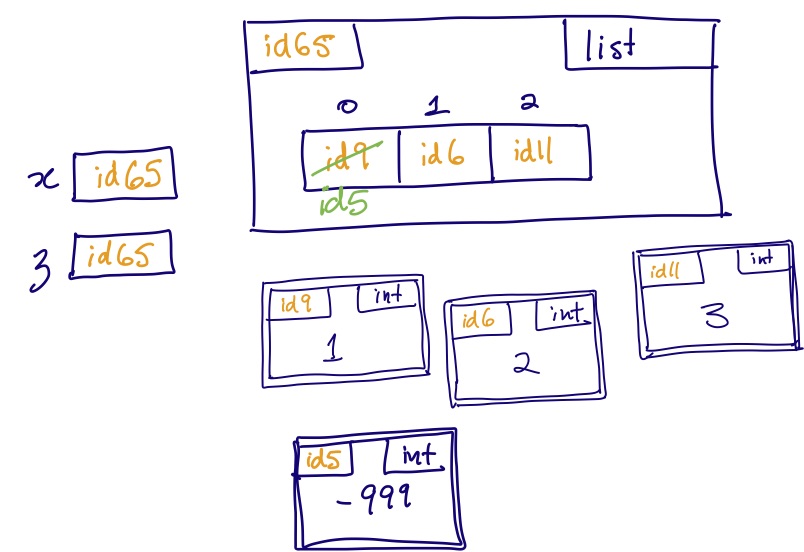
The key thing to notice about this example is that
just by looking at the third line of code, z[0] = -999,
you can’t tell that x has changed;
you need to know that on a previous line, z was made an alias of x.
This is why you have to be careful when aliasing occurs.
Contrast the previous code with this:
>>> x = [1, 2, 3]
>>> y = [1, 2, 3]
>>> y[0] = -999
>>> x # What is the value?
Can you predict the value of x on the last line?
Here, the third line mutates the object that y refers to,
but because it is not the same object that x refers to,
we still see [1, 2, 3] if we evaluate x.
Here’s the state of memory after these lines execute:

Aliasing also exists for immutable data types, but in this case there is never any “action at a distance”, precisely because immutable values can never change.
For example, a tuple is an ordered sequence like a list, but it is immutable.
In the example below, x and z are aliases of a tuple object;
but it is impossible to create a side effect on x by mutating the object that z refers to,
since we can’t mutate tuples at all.
>>> x = (1, 2, 3)
>>> z = x
>>> z[0] = -999
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
Changing a reference is not the same as mutating a value#
What if we did this instead?
>>> x = (1, 2, 3)
>>> z = x
>>> z = (1, 2, 3, 40)
>>> x # What is the value?
Again, we have made x and z refer to the same object.
So when we change z on the third line, does x also change?
This time, the answer is an emphatic no,
and it is because of the kind of change we make on the third line.
Instead of mutating the object that z refers to,
we make z refer to a new object.
This obviously can have no effect on the object that x refers to
(or any object).
Even if we switched the example from using immutable tuples
to using mutable lists, x would be unchanged.
In general,
a statement of the form my_var = _____
never mutates the object that my_var refers to;
all it can ever do is set my_var to refer to a different object.
Keep this rule in mind when you’re writing your own code,
as it’s often easy to confuse mutating values with changing references.
Making a copy to avoid side effects#
Sometimes it makes sense to make a copy of a data structure so that changes can be made to it without any side effect on the original. Keep in mind, though, that this consumes both space and time resources, and is often unnecessary.
Two types of equality#
Let’s look one more time at this code:
>>> x = [1, 2, 3]
>>> y = [1, 2, 3]
>>> z = x
>>> id(x)
4401298824
>>> id(y)
4404546056
>>> id(z)
4401298824
What if we wanted to see whether x and y, for instance, were the same?
Well, we’d need to define precisely what we mean by “the same.”
We can use the == operator
to compare the values stored in the objects they reference.
This is called value equality.
>>> x == y
True
>>> x == z
True
Or, we can use the is operator to compare the ids of the objects they reference.
With is,
we are asking whether two variables reference the exact same object.
This is called identity equality.
>>> x is y
False
>>> x is z
True
All built-in types have an implementation for == so that we can check for value equality;
we’ll later see how to define == for our own classes.
A shortcut with immutable objects#
Because ints are immutable, there isn’t much point in Python creating a separate int object every time your variable needs to refer to, say, 0. They can all refer to the very same object and no harm can be done since the object can never change. This explains the following code:
>>> x = 43
>>> y = 43
>>> z = x
>>> # Of course we see that all three variables have value
>>> # equality. They all reference an int object containing
>>> # 43. Whether or not they are the same int object is
>>> # irrelevant to "==".
>>> x == y
True
>>> x == z
True
>>> # But "is" checks identity equality. We wouldn't have
>>> # expected x and y to reference the same int object.
>>> # But now we know that Python feels free to take a
>>> # short-cut and not create a second int object holding
>>> # the value 43, and in this case it did:
>>> x is y
True
>>> x is z
True
>>> # We can confirm that x and y have the same id:
>>> id(x)
4331557184
>>> id(y)
4331557184
Python can take this short-cut with any value of any immutable type. For example, here we can observe the short-cut with strings:
>>> x = 'foo'
>>> y = 'foo'
>>> x is y
True
But in this example, Python doesn’t take the short-cut:
>>> x = "ice cream"
>>> y = "ice cream"
>>> x is y
False
It turns out that when Python does and doesn’t take the short-cut is quite complex, and it could even change from one version of Python to the next. But it makes no difference to our code’s behaviour; the only reason we need to be aware of it is so that we are not surprised when we see that two variables unexpectedly have identity equality.
Some Python basics that interact with the memory model#
Lists#
Mutating and non-mutating list methods#
Lots of list methods, such as count and index return a value and do not mutate the list they are called on.
>>> lst = [9, 0, 5, 8, 9, 1]
>>> id(lst)
140623854885120
>>> lst.count(9)
2
>>> lst.index(8)
3
>>> id(lst) # lst is still referencing the same list object.
140623854885120
>>> lst
[9, 0, 5, 8, 9, 1] # And the contents of that object are unchanged.
Calls to these methods are easy to trace in the memory model, since nothing is mutated.
Other list methods, such as insert do mutate the list they are called on.
>>> lst.insert(3, 999)
>>> id(lst)
140623854885120 # lst still references that same list object.
>>> lst
[9, 0, 5, 999, 8, 9, 1] # But the contents of it have been changed.
To trace calls to mutating methods using the memory model, we simply have to change what’s inside the list object.
Append vs extend#
By now you know list methods append and extend.
They are similar in that they mutate a list by putting another list into it;
but they create two different structures.
With extend, the individual elements of the new list are added, one by one, to the original list.
>>> new_list = [4, 1, 6]
>>> id(new_list)
140623854891392
>>> lst.extend(new_list)
>>> id(lst)
140623854885120 # lst still references the same list object.
>>> lst
[9, 0, 5, 999, 8, 9, 1, 4, 1, 6] # But we have mutated it.
>>> id(new_list) # new_list, of course, references the same object as before.
140623854891392
>>> new_list # And it is unchanged.
[4, 1, 6]
We extended lst with another list of length 3, so the length of lst went up by 3.
append is different: it adds the new list to the original list as a single new item.
>>> another_list = [5, 10]
>>> id(another_list)
140623854919040
>>> lst.append(another_list)
>>> id(lst)
140623854885120
>>> lst
[9, 0, 5, 999, 8, 9, 1, 4, 1, 6, [5, 10]]
Even though we appended a list of length 2, the length of lst only went up by 1
because we put that entire new list inside lst.
This may feel quite basic. Can you use your understanding of these methods to fill in the missing output here?
>>> lst1 = [1, [2, 3], 4]
>>> lst2 = [5, [6, 7, 7]]
>>> lst1.extend(lst2)
>>> lst1
[1, [2, 3], 4, 5, [6, 7, 7]]
>>> lst2.append(10)
>>> lst2
[5, [6, 7, 7], 10]
>>> lst1
>>> lst2[0] = 15
>>> lst2
[15, [6, 7, 7], 10]
>>> lst1
>>> lst2[1].append(100)
>>> lst2
[15, [6, 7, 7, 100], 10]
>>> lst1
>>> lst1.append(99)
>>> lst1
>>> lst2
>>> lst1[3] = 25
>>> lst1
>>> lst2
>>> lst1[4][1] = 1001
>>> lst1
>>> lst2
Run the code in the Python shell to see if your predictions are correct.
Under the hood of append and extend#
If this exercise raises questions for you, great!
We have glossed over a crucial detail, without which we can’t
reliably predict what our code will do as we continue to use these mutated lists:
Does extend put
the ids of the elements of lst2 into lst1, or does it make copies of these elements?
The answer is that it does not make copies;
instead it puts the ids of the elements of lst2 into lst1, which creates aliasing.
If the aliased objects are mutable, as you know, this allows side effects to happen.
Here’s a smaller example of extend:
>>> stuff = [10, 20]
>>> new_stuff = [30, [40, 50]]
>>> stuff.extend(new_stuff)
>>> stuff
[10, 20, 30, [40, 50]]
This is what’s going on in memory when we run this code:
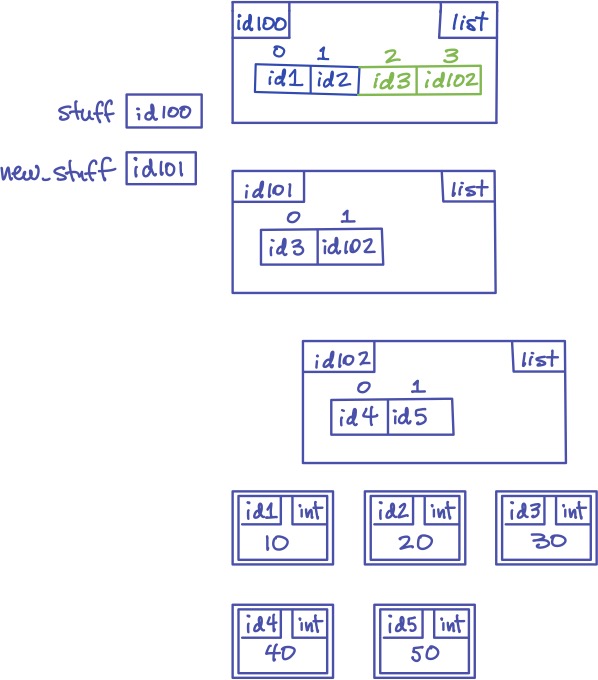
The ids inside the elements of new_stuff, id3 and id102, are added to the end of stuff, creating aliasing.
Here is the same example, but using append instead:
>>> stuff = [10, 20]
>>> new_stuff = [30, [40, 50]]
>>> stuff.append(new_stuff)
>>> stuff
[10, 20, [30, [40, 50]]]
And here is the corresponding memory model diagram:
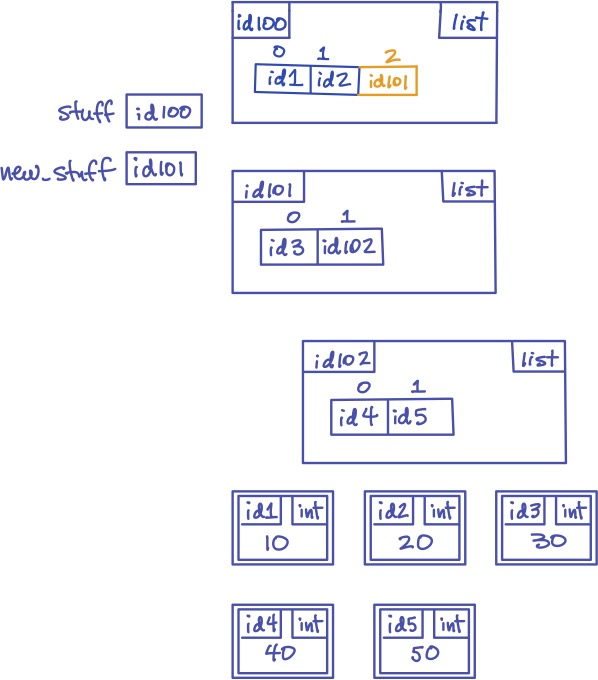
Notice that, this time, the id of the list new_stuff itself, id101, is added to the end of stuff.
This also creates aliasing.
Now that you have a clear picture of what exactly append and extend do, go back and predict again the output of the slightly more complex code above with lst1 and lst2.
What about list operators?#
The operator + can be applied to two lists.
It does not mutate either list.
Instead, it creates a new list containing all the elements of each operand.
For example, this code:
>>> stuff = [10, 20]
>>> new_stuff = [30, [40, 50]]
>>> result = stuff + new_stuff
>>> result
[10, 20, 30, [40, 50]]
yields this memory model:
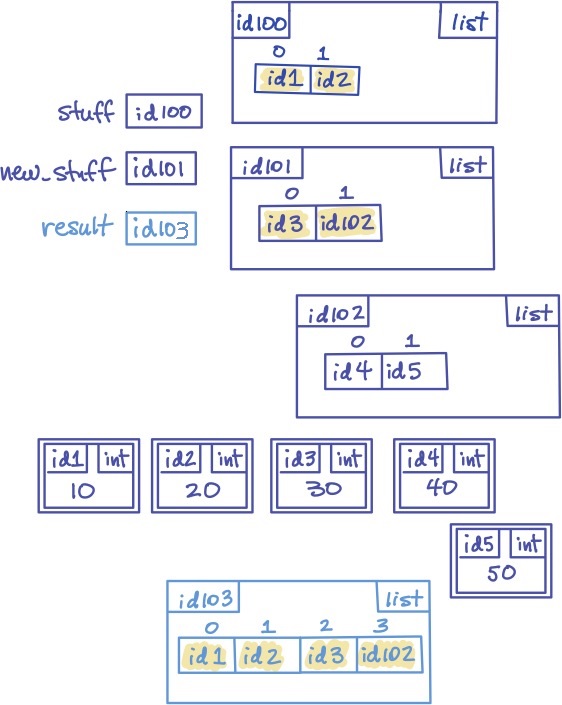
This explains why some of the following mutations to stuff and new_stuff have no effect on result,
but others do.
>>> new_stuff[1].append(99)
>>> new_stuff
[30, [40, 50, 99]]
>>> result
[10, 20, 30, [40, 50, 99]]
>>> stuff[1] = 1111
>>> result
[10, 20, 30, [40, 50, 99]]
>>> stuff.append(2222)
>>> result
[10, 20, 30, [40, 50, 99]]
>>> new_stuff.append(3333)
>>> result
[10, 20, 30, [40, 50, 99]]
>>> new_stuff[1] = 3333
>>> result
[10, 20, 30, [40, 50, 99]]
Another list operator we use a lot is : for slicing.
Slicing always creates a new list, containing the selected elements of the list it was applied to.
For example, this code:
>>> junk = [[1, 2], 3, [4, 5]]
>>> result = junk[1:]
>>> result
[3, [4, 5]]
yields this memory model:
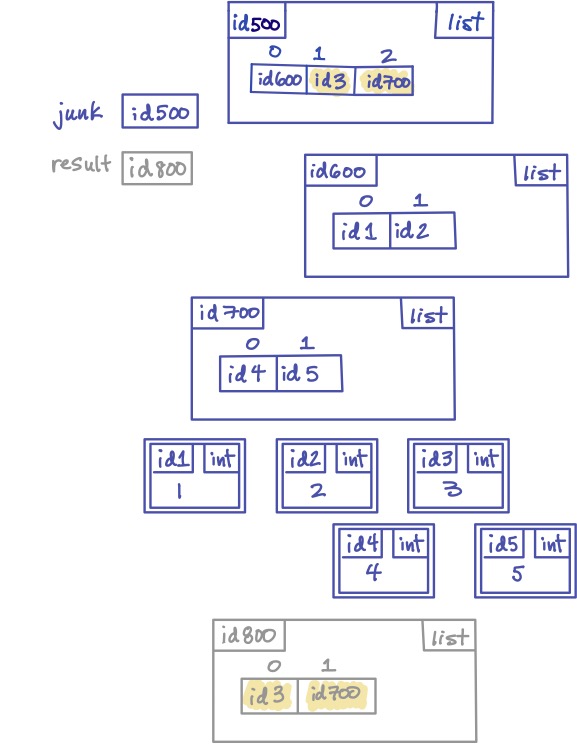
Try writing your own code that mutates junk in different ways to see which of them have an effect on result.
Can you predict the outcome accurately?
For loops#
You’ve written many for-loops that iterate over lists. Here’s a simple one:
>>> nums = [5, 9, 2, 1, 4]
>>> sum = 0
>>> for item in nums:
... sum = sum + item
...
>>> print (sum)
21
Something is going on that is not apparent from the code:
a new variable, item, is created and, on each iteration,
it is assigned to refer to the next element of the list.
It is as if we’d written:
>>> nums = [5, 9, 2, 1, 4]
>>> sum = 0
>>> item = nums[0]
>>> sum = sum + item
>>> item = nums[1]
>>> sum = sum + item
>>> item = nums[2]
>>> sum = sum + item
>>> item = nums[3]
>>> sum = sum + item
>>> item = nums[4]
>>> sum = sum + item
>>> print(sum)
21
This may not seem important, but consider a list of mutable objects (rather than the immutable ints in our list above).
Each time we assign item to refer to one of them, we have aliasing.
Understanding this aliasing, and being aware of the mutability or imutability of our list elements,
will allow you to explain why some loops work and some don’t – and, preferably, to always write loops that work!